By default, this leaderboard is sorted by results with Video-RAG. To view other sorted results, please click on the corresponding cell.
The results are kept on updating!
Introduction from the podcast AI Agents Unleashed: https://www.youtube.com/watch?v=WTs3xHicR_0
By default, this leaderboard is sorted by results with Video-RAG. To view other sorted results, please click on the corresponding cell.
The results are kept on updating!
| # | Model | LLM Params |
Frames | Overall (%) | Short Video (%) | Medium Video (%) | Long Video (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w/o subs | w sub | w Ours | w/o sub | w subs | w Ours | w/o sub | w subs | w Ours | w/o sub | w subs | w Ours | ||||
|
Gemini 1.5 Pro
|
- | 1/0.5 fps | 75.0 | 81.3 | - | 81.7 | 84.5 | 74.3 | 81.0 | 67.4 | 77.4 | ||||
| LLaVA-Video
Bytedance & NTU S-Lab |
72B | 64 | 70.3 | 75.9 | 77.4 | 80.1 | 81.8 | |
68.7 | 73.8 | |
62.1 | 72.2 | |
|
| GPT-4o
OpenAI |
- | 384 | 71.9 | 77.2 | - | 80.0 | 82.8 | 70.3 | 76.6 | 65.3 | 72.1 | ||||
| Qwen2-VL
Alibaba |
72B | 32 | 64.9 | 71.9 | 72.9 | 75.0 | 76.7 | |
63.3 | 69.9 | |
56.3 | 69.2 | |
|
| Long-LLaVA
Amazon |
7B | 64 | 52.9 | 57.1 | 62.6 | 61.9 | 66.2 | |
51.4 | 54.7 | |
45.4 | 50.3 | |
|
| LongVA
NTU S-Lab |
7B | 128 | 52.6 | 54.3 | 62.0 | 61.1 | 61.6 | |
50.4 | 53.6 | |
46.2 | 47.6 | |
|
| LLaVA-NeXT-Video
NTU |
7B | 16 | 43.0 | 47.7 | 50.0 | 49.4 | 51.8 | |
43.0 | 46.4 | |
36.7 | 44.9 | |
|
| Video-LLaVA
PKU |
7B | 8 | 39.9 | 41.6 | 45.0 | 45.3 | 46.1 | |
38.0 | 40.7 | |
36.2 | 38.1 | |
|
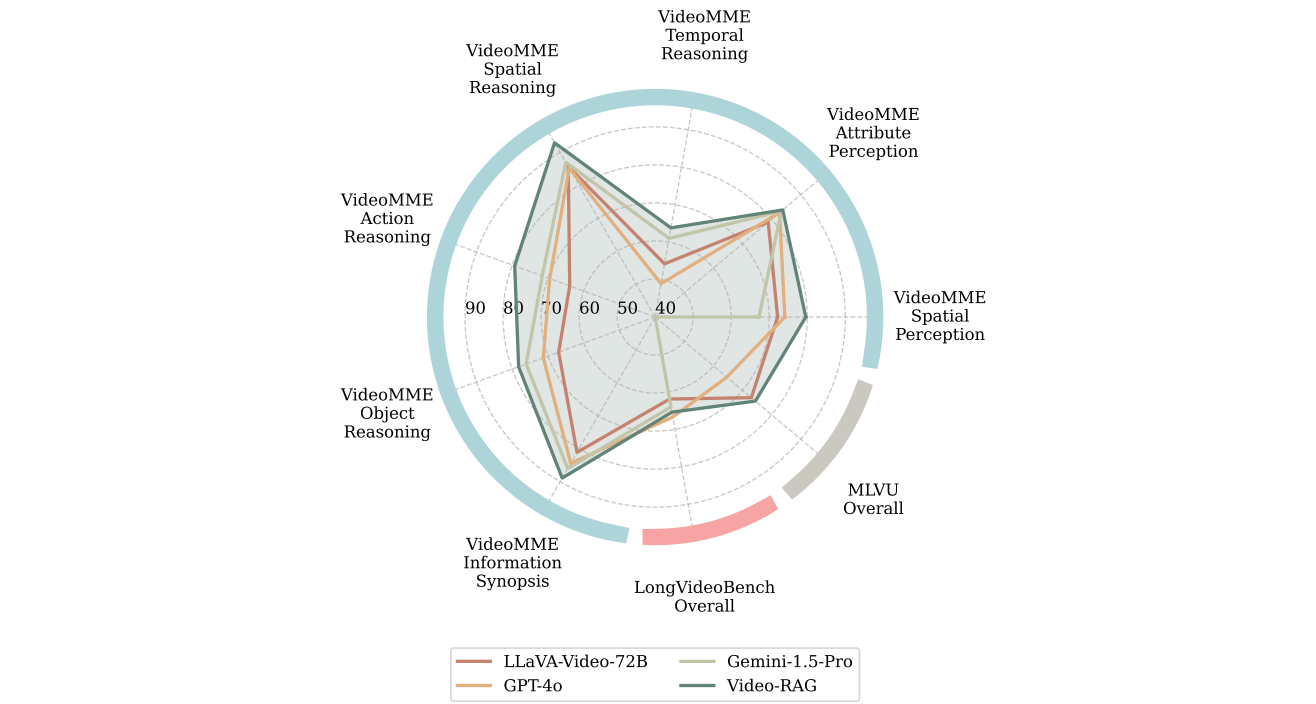
Comparison of the performance of Video-RAG with LLaVA-Video-72B, Gemini-1.5-Pro, and GPT-4o across various benchmarks, including the sub-tasks from Video-MME (here we focus only on those that outperform Gemini-1.5-Pro), LongVideoBench, and MLVU benchmarks.
We apply Video-RAG on LLaVA-Video for visualization.

🔗 Full Video Link: https://www.youtube.com/watch?v=fFjv93ACGo8

🔗 Full Video Link: https://www.youtube.com/watch?v=3m29MQ-qPfg
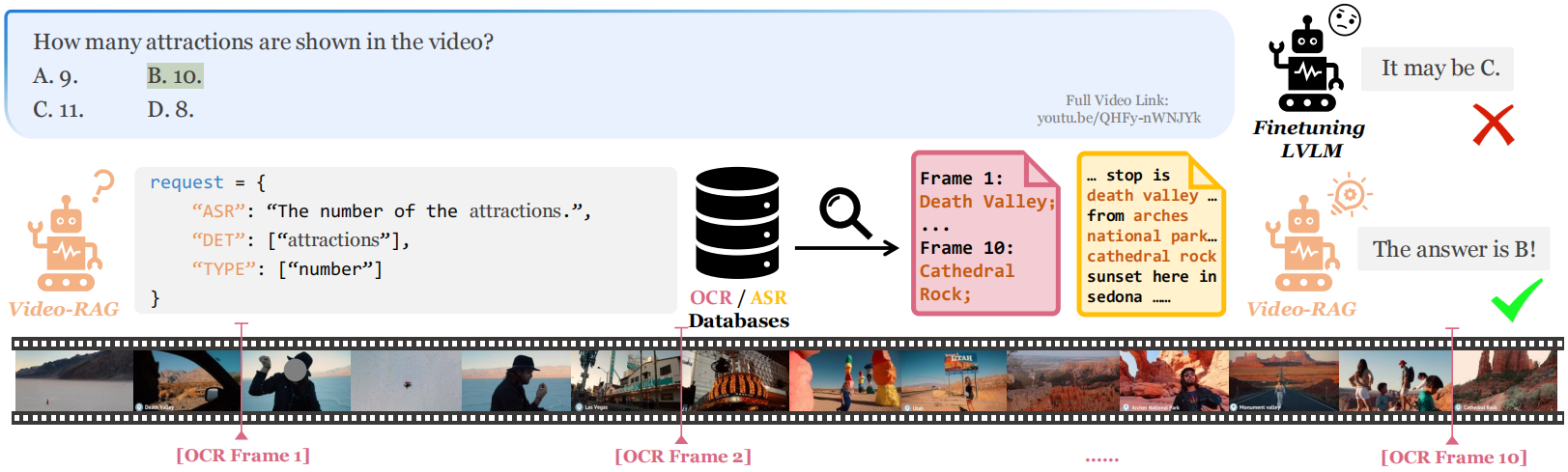
🔗 Full Video Link: https://www.youtube.com/watch?v=QHFy-nWNJYk
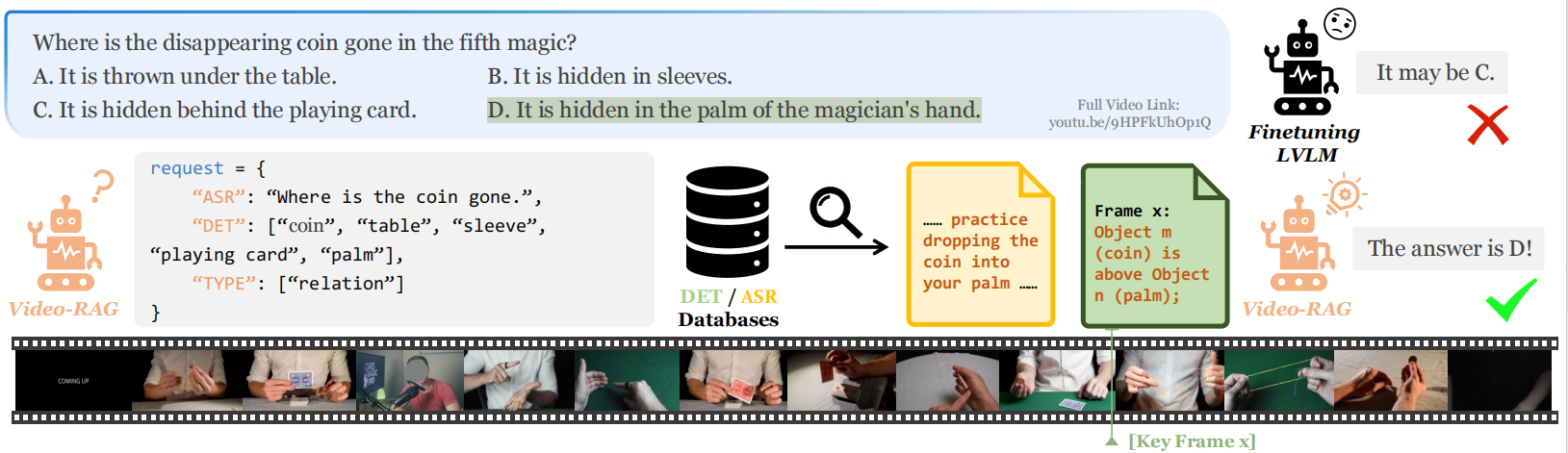
🔗 Full Video Link: https://www.youtube.com/watch?v=9HPFkUhOp1Q
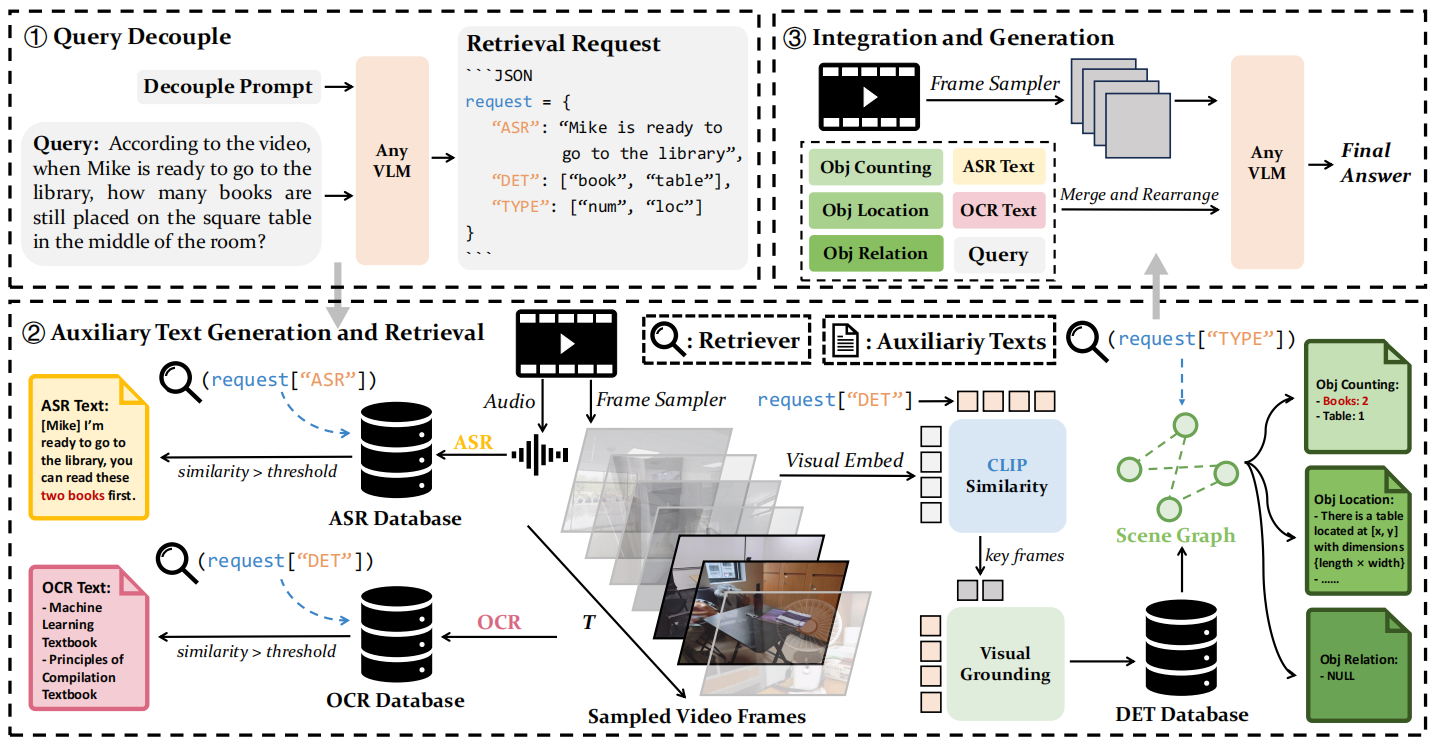
In the query decouple phase, the LVLM is prompted to generate a retrieval request for auxiliary texts. Next, in the auxiliary text generation and retrieval phase, the video is processed in parallel to extract three types of textual information (OCR, ASR, and object detection), and the relevant text is retrieved as the auxiliary text. Finally, in the integration and generation phase, auxiliary texts are combined with the query and the video to generate the response.
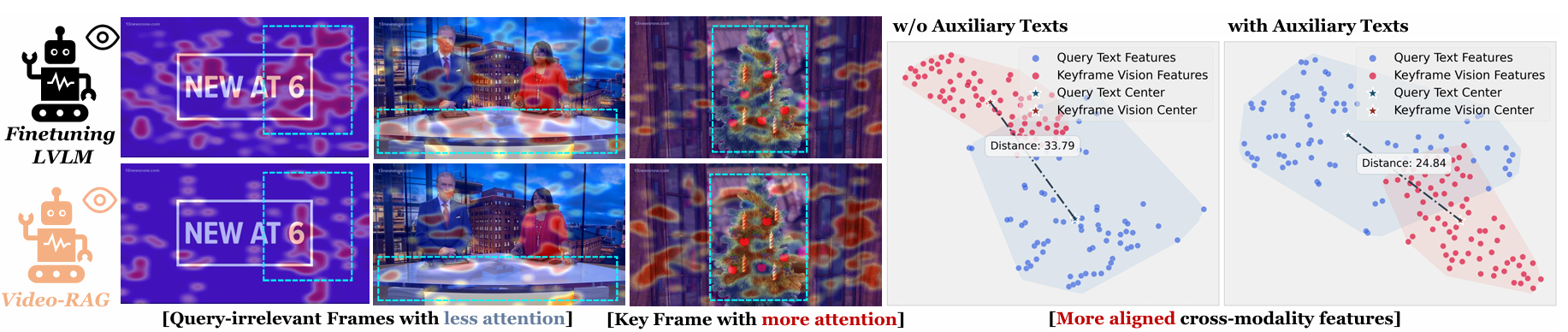
Grad-CAM visualizations of the last hidden state heatmap along with t-SNE visualizations of the user's query and keyframe features of the first example shown in Examples section. As demonstrated, the retrieved auxiliary texts help cross-modality alignment by assisting the model to pay more attention to query-relevant keyframes and thus generate more robust and accurate answers to the user's query.
@misc{luo2024videoragvisuallyalignedretrievalaugmentedlong,
title={Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension},
author={Yongdong Luo and Xiawu Zheng and Xiao Yang and Guilin Li and Haojia Lin and Jinfa Huang and Jiayi Ji and Fei Chao and Jiebo Luo and Rongrong Ji},
year={2024},
eprint={2411.13093},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.13093},
}